Improving Sample Efficiency in Reinforcement Learning Drone Racing using TD-MPC2
Technologies & Tools
Project Images
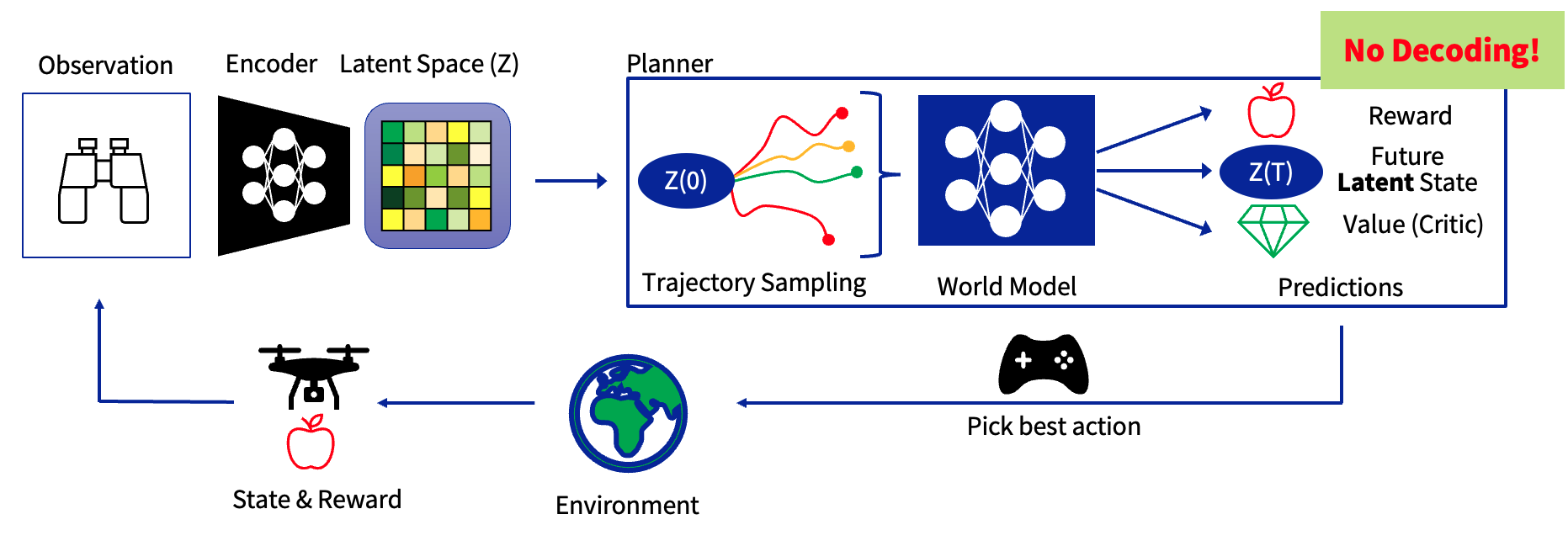
Results & Outcomes
Results: TD-MPC2 demonstrated state-of-the-art performance in state-based drone racing, completing the challenging Split-S track with significantly less environment steps compared to DreamerV3 and PPO, while matching their final lap times. The MPPI planning component proved crucial for exploration. However, vision-based experiments revealed that the algorithm cannot accurately infer velocity from depth images, with consistency losses an order of magnitude higher than state-based training. Teacher-student training enabled vision-based agents to complete laps but produced insufficiently stable policies.
Impact: This work provides critical insights into the capabilities and limitations of modern model-based RL for agile robotics. The exceptional state-based performance demonstrates TD-MPC2's potential for rapid sim-to-real transfer with minimal real-world data. The identified velocity inference bottleneck highlights fundamental challenges in learning dynamics models from partial observations, informing future research directions in vision-based control. These findings are particularly valuable for the drone racing community, offering clear guidelines on sensory requirements and representation learning needs for high-speed autonomous flight.
References
- Hansen et al., "TD-MPC2: Scalable, Robust World Models for Continuous Control," 2024
- Hafner et al., "Mastering Diverse Domains through World Models (DreamerV3)," 2023
- Kaufmann et al., "Champion-level drone racing using deep reinforcement learning," Nature, 2023
- Romero et al., "Dream to fly: Model-based reinforcement learning for vision-based drone flight," 2025
- Song et al., "Flightmare: A Flexible Quadrotor Simulator," Conference on Robot Learning, 2021